Join the HathiTrust Research Center (HTRC) and InPhO Project for a half-day tutorial on HathiTrust data access and topic modeling at JCDL 2015 in Knoxville, TN on Sunday, June 21, 2015, 9am-12pm!
Topic Exploration with the HTRC Data Capsule for Non-Consumptive Research
Organizers: Jaimie Murdock, Jiaan Zeng and Robert McDonald
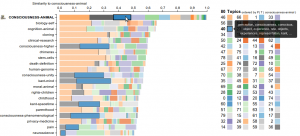
Abstract: In this half-day tutorial, we will show 1) how the HathiTrust Research Center (HTRC) Data Capsule can be used for non-Âconsumptive research over collection of texts and 2) how integrated tools for LDA topic modeling and visualization can be used to drive formulation of new research questions. Participants will be given an account in the HTRC Data Capsule and taught how to use the workset manager to create a corpus, and then use the VM’s secure mode to download texts and analyze their contents. [tutorial paper]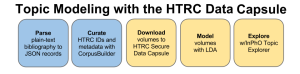
Organizers: Jaimie Murdock, Jiaan Zeng and Robert McDonald
Abstract: In this half-day tutorial, we will show 1) how the HathiTrust Research Center (HTRC) Data Capsule can be used for non-Âconsumptive research over collection of texts and 2) how integrated tools for LDA topic modeling and visualization can be used to drive formulation of new research questions. Participants will be given an account in the HTRC Data Capsule and taught how to use the workset manager to create a corpus, and then use the VM’s secure mode to download texts and analyze their contents. [tutorial paper]

We draw your attention to the astonishingly low half-day tutorial fees:
Half-Day Tutorial/Workshop Early Registration (by May 22!)
ACM/IEEE/SIG/ASIS&T Members – $70
Non-ACM/IEEE/SIG/ASIS&T Members – $95
ACM/IEEE/SIG/ASIS&T Student – $20
Non-member Student – $40Half-Day Tutorial/Workshop Late/Onsite Registration
ACM/IEEE/SIG/ASIS&T Members – $95
Non-ACM/IEEE/SIG/ASIS&T Members – $120
ACM/IEEE/SIG/ASIS&T Student – $40
Non-member Student – $60
Hope to see you there!