This week, I launched The InPhO Topic Explorer. Through an interactive visualization, The InPhO Topic Explorer exposes one way search engine results are generated and allows more focused exploration than just a list of related documents. It uses the LDA machine learning algorithm, the explorer infers topics from arbitrary text corpora. The current demo is trained on the Stanford Encyclopedia of Philosophy, but I will be expanding this to other collections in the next few weeks.
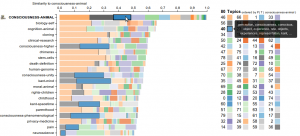
The color bands within each article’s row show the topic distribution within that article, and the relative sizes of each band indicates the weight of that topic in the article. The full width of each row indicates the similarity to the focus article. Each topic’s label and color is arbitrarily assigned, but is consistent across articles in the browser per topic.
Display options include topic normalization, alphabetical sort and topic sort. By normalizing topics, the full width of each bar expands and topic weights per document can be compared. By clicking a topic, the documents will reorder acoording to that topic’s weight and topic bars will reorder according to the topic weights in the highest weighted document.
By varying the number of topics, one can get a finer or coarser-grained analysis of the areas discussed in the articles. The visualization currently has 20, 40, 60, 80, 100, and 120 topic models for the Stanford Encyclopedia of Philosophy.
In contrast to a search engine, which displays articles based on a similarity measure, the topic explorer allows you to reorder results based on what you’re interested in. For example, if you’re looking at animal consciousness (80 topics), you can click on topic 46 to see those that are closest in the “animals” category, while 46 shows “consciousness” and 42 shows “perception” (arbitrary labels chosen). Some topics have a lot of words like “theory”, “case”, “would”, and “even”. These general argumentative topics can be indicative of areas where debate is still ongoing.
In early explorations, the visualization already highlights some interesting phenomena:
- For central articles, such as kant (40 topics), one finds that a single topic (topic 30) comprises much of the article. By increasing the number of topics, such as to kant (120 topics), topic 77 now captures the “kant”-ness of the article, but several other components can now be explored. This shows the value of having multiple topic models.
- For creationism (120 topics), one can see that the particular blend of topics generating that article is truly an outlier, with the probability only just over .5 of generating the next closest document; compare this to the distribution of top articles related to animal-consciousness (120 topics) or kant (120 topics).  Can you find other outliers in the SEP?
The underlying dataset was generated using the InPhO VSM module’s LDA implementation. See Wikipedia: Latent Dirichlet Allocation for more on the LDA topic modeling approach or “Probabilistic Topic Models” (Blei, 2012) for a recent review.
Source code and issue tracking are available at GitHub.
Please share any notes in the comments below!